前言
本篇博客主要记录我学习 complier 的过程。
主要参考实验: PKU 编译原理实验↗
主要参考书籍: 《编译器设计 (第二版)》、《编译方法、技术与实践》
正文
9-10
Lv0. 环境配置
记录一下上一周完成的:根据北大编译实验在线文档完成了 Lv0. 环境配置 配置了 docker 源,并且根据 docker 写了一个启动脚本,我选择了 c/c++ 路线使用 cmake 进行编译。
脚本如下:
#!/bin/bash
docker run -it --rm -v $(pwd):/root/compiler maxxing/compiler-dev bash -c "
cd compiler &&
cmake -DCMAKE_BUILD_TYPE=Debug -B build &&
cmake --build build &&
cd build &&
bash
"其中第一行是根据 Maxxing 的 docker run 脚本改的启动脚本,使用了 $(pwd) 增加脚本的通用性.
后面的内容很容易理解.
Lv1. main 函数
Lv1.1. 编译器的结构
编译器通常由以下几个部分组成:
- 前端: 通过词法分析和语法分析, 将源代码解析成抽象语法树 (abstract syntax tree, AST). 通过语义分析, 扫描抽象语法树, 检查其是否存在语义错误.
- 中端: 将抽象语法树转换为中间表示 (intermediate representation, IR), 并在此基础上完成一些机器无关优化.
- 后端: 将中间表示转换为目标平台的汇编代码, 并在此基础上完成一些机器相关优化.
一些英文用语
- 词法分析器 (lexer)
- 语法分析器 (parser)
- 字节流 (byte stream)
- 单词流 (token stream)
- 中间表示 (IR)
- 抽象语法树 (AST)
词法分析的作用, 是把字节流转换为单词流 (token stream). 语法分析的目的, 按照程序的语法规则, 将输入的 token 流变成程序的 AST. 在语法分析的基础上, 编译器会对 AST 做进一步分析, 以期 “理解” 输入程序的语义, 为之后的 IR 生成做准备. 编译器通常会将 AST 转换为另一种形式的数据结构, 我们把它称作 IR. IR 的抽象层次比 AST 更低, 但又不至于低到汇编代码的程度. 在此基础上, 无论是直接把 IR 进一步转换为汇编代码, 还是在 IR 之上做出一些优化, 都相对更容易.(比较出名的 LLVM 里面就有很多 IR) 编译器进行的最后一步操作, 就是将 IR 转换为目标代码, 也就是目标指令系统的汇编代码.
Lv1.2. 语法/词法分析初见
由于生在一个好时代,我们想要实现一个效率蛮不错的词法/语法分析器,并不需要手写递归下降分析器。不过我先在这里放一个网址,可以以后留着来看 Kaleidoscopea↗. 现在的工具可以根据正则表达式和 EBNF 生成词法/语法分析器.
EBNF, 即 Extended Backus–Naur Form↗, 扩展巴科斯范式, 可以用来描述编程语言的语法.
9-11
示例:
int main() {
// 忽略我的存在
return 0;
}的语法用 EBNF 表示为
CompUnit ::= FuncDef;
FuncDef ::= FuncType IDENT "(" ")" Block;
FuncType ::= "int";
Block ::= "{" Stmt "}";
Stmt ::= "return" Number ";";
Number ::= INT_CONST;通过推导可以得到
"int" IDENT "(" ")" "{" "return" INT_CONST ";" "}"由于活在一个好的时代,在 C/C++中,我们可以使用 Flex 和 Bison 来分别生成词法分析器和语法分析器.
- Flex 用来描述 EBNF 中的终结符部分, 也就是描述 token 的形式和种类. 你可以使用正则表达式来描述 token.
- Bison 用来描述 EBNF 本身, 其依赖于 Flex 中的终结符描述. 它会生成一个 LALR parser.
关于 Flex 和 Bison 的学习,Maxxing 推荐参考 Calc++↗ 这里先行放置一下,等以后过来可以学习一下.
Flex 将会读取 *.l 文件中描述的词法规则,Bison 将会读取 *.y 文件中描述的语法规则.由于这两个文件是互相依赖的 由于 Flex 和 Bison 生成的 lexer 和 parser 会互相调用, 所以这两个文件里的内容也相互依赖.
这两种后缀的文件的结构都是:
// 这里写一些选项, 可以控制 Flex/Bison 的某些行为
%{
// 这里写一些全局的代码
// 因为最后要生成 C/C++ 文件, 实现主要逻辑的部分都是用 C/C++ 写的
// 难免会用到头文件, 所以通常头文件和一些全局声明/定义写在这里
%}
// 这里写一些 Flex/Bison 相关的定义
// 对于 Flex, 这里可以定义某个符号对应的正则表达式
// 对于 Bison, 这里可以定义终结符/非终结符的类型
%%
// 这里写 Flex/Bison 的规则描述
// 对于 Flex, 这里写的是 lexer 扫描到某个 token 后做的操作
// 对于 Bison, 这里写的是 parser 遇到某种语法规则后做的操作
%%
// 这里写一些用户自定义的代码
// 比如你希望在生成的 C/C++ 文件里定义一个函数, 做一些辅助工作
// 你同时希望在之前的规则描述里调用你定义的函数
// 那么, 你可以把 C/C++ 的函数定义写在这里, 声明写在文件开头实验中给出的实例代码可以在 这里↗ 看一看.
在誊抄了 lab 中的代码后,我也是成功运行了这个简易 “编译器” 了.
当然,运行 complier 的时候记得参数中文件的地址,比如示例文件中 hello.c 在 ../ 中,别忘了修改参数,不然会报错
compiler: /root/compiler/src/main.cpp:27: int main(int, const char **): Assertion `yyin' failed.
Aborted (core dumped)9-14
强烈推荐使用 VScode 中的 Yash 插件,可以高亮 Flex & Bison 的语法以及纠错.
在 parser 里可以使用 unique_ptr 智能指针来很好的减轻内存管理的压力.
基本特性:
- 自动管理内存(RAII)
- 独占所有权(不能复制,只能移动)
- 离开作用域时自动删除所指向的对象
示例:
#include <memory>
#include <string>
// 基本使用示例
void uniquePtrBasics() {
// 创建 unique_ptr
std::unique_ptr<std::string> ptr1 = std::make_unique<std::string>("Hello");
// 或者使用 new(不推荐)
std::unique_ptr<std::string> ptr2(new std::string("World"));
// 访问内容
std::cout << *ptr1 << std::endl; // 解引用
std::cout << ptr1->length() << std::endl; // 成员访问
// 移动语义(转移所有权)
std::unique_ptr<std::string> ptr3 = std::move(ptr1);
// 现在 ptr1 为空,ptr3 拥有字符串
// 离开作用域时自动删除内存
}Union 联合体
基本特性:
- 所有成员共享同一块内存
- 大小等于最大成员的大小
- 同一时间只能使用其中一个成员
示例
// 基本 union 示例
union BasicUnion {
int int_val;
float float_val;
char char_val;
};
int main() {
BasicUnion u;
// 只能同时使用一个成员
u.int_val = 42;
cout << "int: " << u.int_val << endl; // 输出: 42
u.float_val = 3.14f;
cout << "float: " << u.float_val << endl; // 输出: 3.14
cout << "int: " << u.int_val << endl; // 输出: 垃圾值,因为被覆盖了
return 0;
}Lv1.3. 解析 main 函数
本节的内容需要我处理以下 EBNF:
CompUnit ::= FuncDef;
FuncDef ::= FuncType IDENT "(" ")" Block;
FuncType ::= "int";
Block ::= "{" Stmt "}";
Stmt ::= "return" Number ";";
Number ::= INT_CONST;我使用了智能指针的方案,进一步理解了面向对象编程中 多态 这一个概念后,我开始照着 Maxxing 的示例进行编写. 我创建了 ast.h, ast.cpp, include.h , 分别用来保存 ast 中相关类的定义,ast 中各个类中 Dump() 函数的编写.以及原来的一些头文件.
ast.h
#pragma once
#include "include.h"
class BaseAST {
public:
virtual ~BaseAST() = default;
virtual void Dump() const = 0;
};
class CompUnitAST : public BaseAST {
public:
std::unique_ptr<BaseAST> fun_def;
void Dump() const override;
};
class FunDefAST : public BaseAST {
public:
std::unique_ptr<BaseAST> fun_type;
std::string ident;
std::unique_ptr<BaseAST> block;
void Dump() const override;
};
class FunTypeAST : public BaseAST {
public:
std::string tp;
void Dump() const override;
};
class BlockAST : public BaseAST {
public:
std::unique_ptr<BaseAST> stmt;
void Dump() const override;
};
class StmtAST : public BaseAST {
public:
std::string retrn = "return";
std::unique_ptr<BaseAST> number;
std::string fenhao = ";";
void Dump() const override;
};
class NumberAST : public BaseAST {
public:
int int_const;
void Dump() const override;
};
ast.cpp
#include "include.h"
#include "ast.h"
void CompUnitAST :: Dump() const {
std::cout << "CompUnitAST { ";
fun_def -> Dump();
std::cout << " } ";
}
void FunDefAST :: Dump() const{
std::cout << "FuncDefAST { ";
fun_type -> Dump();
std::cout << ident << " ( ) ";
block -> Dump();
std::cout << " } " ;
}
void FunTypeAST :: Dump() const{
std::cout << "FuncTypeAST { ";
std::cout << tp ;
std::cout << " } ";
}
void BlockAST :: Dump() const{
std::cout << "BlockAST { ";
stmt -> Dump() ;
std::cout << " } ";
}
void StmtAST :: Dump() const{
std::cout << "StmtAST { ";
std::cout << retrn;
number -> Dump();
std::cout << fenhao;
std::cout << " } ";
}
void NumberAST :: Dump() const{
std::cout << int_const;
}了解了智能指针的用法后,这些还是比较容易写出来的,就是有点费时间.
然后在 sysy.y 照着示例将所有字符串更新成为 AST 类即可.
写完后我遇到了两个问题,第一是在 Stmt 返回的第二个参数返回的类型,和我设计的预期不符合
Stmt
: RETURN Number ';' {
auto numbr = new StmtAST();
numbr -> number = unique_ptr<BaseAST>($2);
$$ = numbr;
}
;这其实是照着教程给非终结符定义的时候将 Number 定义成了 int_val 导致 ($2) 的返回值是一个 int ,导致错误.
把 Number 加入了 ast_val 后就成功解决了.
第二个问题是链接的时候出现问题, *.cpp 类型的文件都不能放在别的文件的 include path 当中,会重复定义.
删除了这些 ast.cpp 就 ok 了.
得到结果

9-15
Lv1.4. IR 生成
这一节,演示代码几乎消失不见了,只剩下我们需要实现的目标:
- 我们应该生成一个 Koopa IR 程序.
- 程序中有一个名字叫 main 的函数.
- 函数里有一个入口基本块.
- 基本块里有一条返回指令.
- 返回指令的返回值就是 SysY 里 return 语句后跟的值, 也就是一个整数常量.
并且最后生成一个这个程序:
fun @main(): i32 { // main 函数的定义
%entry: // 入口基本块
ret 0 // return 0
}打算用 vector<unique_ptr<xxx>> 之类的来存.今日进度不佳.
9-16
我定义好了 Ir.h 和 Ir.cpp 里的内容,定义好了如何 IR 里的内容.方法和 AST 类似,Dump() 函数也类似.这回也是纯纯手写代码上了.
现在就是写 IRGenerator 的时间,我本来想使用函数式定义这个 GENERATOR 不过考虑到这个函数可能会过于庞大,还是用类来定义了.
这是我初版的 IRGenerator 的定义:
class IRGenerator {
private:
std::unique_ptr<IRProgram> program;
static int blockcount;
public:
IRGenerator(){};
void visitCompUnit(const CompUnitAST* ast);
void visitFunDef(const FunDefAST* ast);
void visitFunType(const FunTypeAST* ast);
void visitBlock(const BlockAST* ast);
void visitStmt(const StmtAST* ast);
void visitNumber(const NumberAST* ast);
std::unique_ptr<IRProgram> get_irprogram();
};比较好理解,不过这里每一个 visit 函数的参数并没有使用 unique_ptr<BaseAST> 的类型,使用了各种 AST 分别的类的指针,会安全一些.
但是,我在之前生成 AST 的时候,基于多态性质,利用的所有指针都是 BaseAST 类型的,怎么才能优秀的传入 visit 函数的参数中呢?
if (ast && ast->fun_def) {
if (auto func_def = dynamic_cast<FunDefAST*>(ast->fun_def.get())) {
visitFuncDef(func_def);
}
}这个代码是 ai 生成的 ,我觉得很有意思,它做了这些事情:
void IRGenerator::visitCompUnit(const CompUnitAST* ast) {
// 步骤1:检查 ast 指针是否有效
if (!ast) {
std::cout << "CompUnitAST is null!" << std::endl;
return;
}
// 步骤2:检查 fun_def 成员是否存在
if (!ast->fun_def) {
std::cout << "fun_def is null!" << std::endl;
return;
}
// 步骤3:检查 fun_def 的实际类型是否是 FunDefAST
auto func_def = dynamic_cast<const FunDefAST*>(ast->fun_def.get());
if (!func_def) {
std::cout << "fun_def is not a FunDefAST!" << std::endl;
return;
}
// 步骤4:安全地调用 visitFuncDef
visitFuncDef(func_def);
}dynamic_cast<目标类型>(源对象) 这个函数的作用是尝试将源对象转化成目标类型, 如果失败返回 nullptr,十分满足我的需求.不过,需要注意的是,该操作虽然安全,但是有性能开销,还有一种函数是 static_cast 这个会快速一些,但是会导致未定义行为,以后的实践可能会用到这个优化.
我觉得可以学习这种写法,优秀的解决了参数类型的问题,还带有检测 ast 以及 ast -> fun_def 是否为空的问题.
9-17
顺利的写出了 IR 的内容.
修改了 IRGenerator 里 visit 函数的定义 , 给 visit Block 等函数添加了 IRBasicBlock* 类的参数.
给参数是指针的函数传递参数的时候,要使用 std::move() 转移所有权,不然会出现问题;
Lv1.5. 测试
按照要求,我更新了我的 run.sh 的内容,添加了测试的功能.
#!/bin/bash
# 获取项目目录的绝对路径
PROJECT_DIR=$(pwd)
# 检查第一个参数
if [ "$1" = "test" ]; then
# 测试模式:运行 autotest
sudo docker run -it --rm -v $PROJECT_DIR:/root/compiler maxxing/compiler-dev \
autotest -koopa -s "$2" /root/compiler
else
# 默认模式:进入交互式 bash
sudo docker run -it --rm -v $PROJECT_DIR:/root/compiler maxxing/compiler-dev bash -c "
cd compiler &&
cmake -DCMAKE_BUILD_TYPE=Debug -B build &&
cmake --build build &&
cd build &&
bash
"
fi输入 ./run.sh test lv1 就可以 开始测试了.
这回没过第二个测试点,原来是遗留的作业没有做完,多行匹配.
CSDN 经过几年的运营 ,越来越差了, 基本都是垃圾, 不垃圾的需要冲会员.
在 .l 里写了多行匹配的正则表达式之后,就完成了测试.
Lv2. 初试目标代码生成
Lv2.1. 处理 Koopa IR
由于我写出来的 IRGenerator 是存储在内存当中的,所以这一节跳过.
Lv2.2. 目标代码生成
我需要把
fun @main() : i32 {
%entry0 :
ret 0
}变成
.text
.globl main
main:
li a0, 0
ret这样的汇编代码,我准备在每个 Value 的类中添加转化成 Risc-V 的代码,应该不会很复杂.
9-19
我在所有的 value basicblock function program IR 类中添加了 To_Riscv 函数,按照实例代码翻译即可,还是很容易的.
这里我给之前的代码做出一些修改,将 return Number 这个操作合并到 ReturnValue 这个类中,这样就不会出现生成 koopa IR 和生成 RiscV 汇编的时候出现 ret 和 number 顺序出错的问题了.
Lv2.3. 测试
我又更新了我的 run.sh 增加了一个参数 ,可以手动选择测试的时候要 -koopa 还是 -riscv .
这是更新后的代码
#!/bin/bash
# 获取项目目录的绝对路径
PROJECT_DIR=$(pwd)
# 检查第一个参数
if [ "$1" = "test" ]; then
# 测试模式:运行 autotest
sudo docker run -it --rm -v $PROJECT_DIR:/root/compiler maxxing/compiler-dev \
autotest "$2" -s "$3" /root/compiler
else
# 默认模式:进入交互式 bash
sudo docker run -it --rm -v $PROJECT_DIR:/root/compiler maxxing/compiler-dev bash -c "
cd compiler &&
cmake -DCMAKE_BUILD_TYPE=Debug -B build &&
cmake --build build &&
cd build &&
bash
"
fi可能是之前写 AST 和 IR 都选择了纯手写,保存 IR 到内存,所以第二章需要增添的内容挺少的,顺利通过了第二章。
Lv3. 表达式
Lv3.1. 一元表达式
本章我要完成这样一个 EBNF
Stmt ::= "return" Exp ";";
Exp ::= UnaryExp;
PrimaryExp ::= "(" Exp ")" | Number;
Number ::= INT_CONST;
UnaryExp ::= PrimaryExp | UnaryOp UnaryExp;
UnaryOp ::= "+" | "-" | "!";要将 Stmt 重写.
9-21
天下英雄如过江之鲫
我感觉要走的路还是太长了,走着走着就迷茫了.
我定义好了 AST 并且写出了对应的 Bison 内容,明天写 IR 的内容.
9-22
这是 maxxing 给出的实例代码
int main() {
return +(- -!6); // 看起来像个颜文字
}我们只看
+(- -!6) 根据 EBNF 规则,该语句可以这样被推导出来
Exp -> UnrayExp
-> UnrayOp UnrayExp
-> "+" PrimaryExp
-> "+" "(" Exp ")"
-> "+" "(" UnrayExp ")"
-> "+" "(" UnrayOp UnrayExp ")"
-> "+" "(" "-" UnrayOp UnrayExp ")"
-> "+" "(" "-" "-" UnrayOp UnrayExp ")"
-> "+" "(" "-" "-" "!" PrimaryExp ")"
-> "+" "(" "-" "-" "!" Number ")"
-> "+" "(" "-" "-" "!" INT_CONST ")" 我貌似发现了一些问题,我的 Bison 文件中,括号里的 Exp 好像并没有被优先处理。
得 ATFA 了.
实际上我可能对 parser 的工作原理还完全没有了解.
我只知道它在做上述推导规则的逆过程
Bison 使用了 LR 的推导规则, LR 是 Left-to-right, Rightmost derivation 的缩写. 这是一种自底向上的 Parser 规则.
还有一些其他的 Parser 规则,比如 LL 以及其他,这里用 ai 做了个表.
| Parser 类型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 递归下降 | 简单直观,容易调试 | 只支持 LL(k),左递归需要改写 | 简单语言,原型开发 |
| LR/LALR | 强大,支持大多数实际文法 | 冲突难调试,表格较大 | 生产级编译器 |
| GLR | 支持有歧义文法 | 复杂,性能开销大 | 自然语言处理,复杂 DSL |
| Parser Combinator | 模块化,类型安全 | 性能可能不如表驱动 | 函数式语言,小型 DSL |
| PEG | 无歧义,支持任意前瞻 | 某些文法表达困难 | 现代编程语言 |
LR PARSER
关于 LR 的原理,我来简单说下我的理解.
我觉得要理解 LR Parser 的实现过程,理解 ACTION table 和 GOTO table 是怎么生成的会比较关键一些.
不过我们等会再说这两个 table 是怎么生成,我们先看看 LR Parser 会进行哪些操作.
LR Parser 会严格的按照两张 table (ACTION & GOTO) 对 两个栈 进行操作:
- 状态栈 : 保存解析过程中的状态序列
- 符号栈 : 保存已经识别出的文法符号 (终结符和非终结符)
而操作有四种:
- Shift (移进) : 从输入流中读入一个符号,并推入符号栈,同时将新状态推入状态栈
- Reduce (归约) : 从符号栈的栈顶 pop 出若干元素 ,从栈顶弹出若干符号(某条语法规则的右侧),压入一个新的非终结符(该规则的左侧),并根据 GOTO 表压入新状态
- Accept (接受) : 解析成功完成
- Error (错误) : 检测到语法错误
LR parser 绝大部分时候只会干两件事情 Shift 和 Reduce.
首先的问题是,什么是状态?
状态表示 当前解析进度的所有可能情况的集合
而这个情况 我们可以用 项目 来描述,
项目 大致长这样
Stmt -> RETURN • Exp ';'和 EBNF 语句几乎完全一样,但是多了一个点.
这个点是解析进度标记,在这个点前面的语句代表已经识别的符号,点后面的代表还需要识别的符号.
那么上述的 项目 可以理解为 已经看到 RETURN,现在期望 Exp
既然我期望得到他,那我就把所有能得到他的项目创建成一个状态,比如说这样
核心: Stmt → RETURN • Exp ';'
CLOSURE(I1):
Stmt → RETURN • Exp ';'
Exp → • UnaryExp [因为点后是 Exp]
UnaryExp → • PrimaryExp [因为点后是 UnaryExp]
UnaryExp → • UnaryOp UnaryExp
PrimaryExp → • '(' Exp ')' [因为点后是 PrimaryExp]
PrimaryExp → • Number
UnaryOp → • '+' [因为点后是 UnaryOp]
UnaryOp → • '-'
UnaryOp → • '!'
Number → • INT_CONST [因为点后是 Number]这样我们就得到了一个 状态 即 项目 的集合.
我们已经解析完了 RETURN 这时候,如果我们 读取到了一个新的 TOKEN ,比如说 “42” 这是一个 INT_CONST 我们就知道我们可以进入一个新的状态了.
这个时候我们可以得到一条 ACTION 表的语句 当我们在状态 I1 , 然后读取到了 INT_CONST 的时候,我们把这个 INT_CONST 压入 到符号栈栈顶 同时把状态 I2 压入状态栈的栈顶
简写成
| ACTION | INT_CONST |
|---|---|
| I1 | s2 |
现在的符号栈栈顶是 I2
CLOSURE(I2)
Number → INT_CONST • [归约项目]这个项目的 点 已经走到了尽头,代表他可以归约.
这个时候我们压入 NUMBER , pop 了状态栈的顶部元素 I2 回到了 I1;
这个时候我们会进入这样一个状态空间
PrimaryExp → • Number假设上面的这个状态是 I7 ,那么我们就得到一个 goto 表的项了
| GOTO | NUMBER |
|---|---|
| I1 | I7 |
显然, GOTO 表只处理非终结符
不过 Bison 会使用 GOTO 函数 的方法去构造这个表,这里就不再赘述,不过核心思想就是我刚才演示的那两条.
我们来看个例子
注:下面的 GOTO 皆为 GOTO 函数的意思,并非 GOTO 表
GOTO 函数:在构造 LR 自动机时使用的状态转移函数
- 格式: GOTO (状态, 符号) = 新状态
- 可以处理任何文法符号(终结符和非终结符)
- 用于构造状态机和生成分析表
第一步:从语法生成项目集和状态
这是 maxxing 给的语法规则 (ENBF)
(0) S' → Stmt [增广文法]
(1) Stmt → RETURN Exp ';'
(2) Exp → UnaryExp
(3) UnaryExp → PrimaryExp
(4) UnaryExp → UnaryOp UnaryExp
(5) PrimaryExp → '(' Exp ')'
(6) PrimaryExp → Number
(7) UnaryOp → '+'
(8) UnaryOp → '-'
(9) UnaryOp → '!'
(10) Number → INT_CONST状态生成过程
状态 I0(初始状态)
核心项目: S' → • Stmt
CLOSURE(I0):
S' → • Stmt
Stmt → • RETURN Exp ';' [因为点后是 Stmt]GOTO(I0, RETURN) = I1
核心: Stmt → RETURN • Exp ';'
CLOSURE(I1):
Stmt → RETURN • Exp ';'
Exp → • UnaryExp [因为点后是 Exp]
UnaryExp → • PrimaryExp [因为点后是 UnaryExp]
UnaryExp → • UnaryOp UnaryExp
PrimaryExp → • '(' Exp ')' [因为点后是 PrimaryExp]
PrimaryExp → • Number
UnaryOp → • '+' [因为点后是 UnaryOp]
UnaryOp → • '-'
UnaryOp → • '!'
Number → • INT_CONST [因为点后是 Number]GOTO(I1, INT_CONST) = I2
Number → INT_CONST • [归约项目]GOTO(I1, ’+’) = I3
UnaryOp → '+' • [归约项目]GOTO(I1, ’-’) = I4
UnaryOp → '-' • [归约项目]GOTO(I1, ’!’) = I5
UnaryOp → '!' • [归约项目]GOTO(I1, ’(’) = I6
核心: PrimaryExp → '(' • Exp ')'
CLOSURE(I6):
PrimaryExp → '(' • Exp ')'
Exp → • UnaryExp
UnaryExp → • PrimaryExp
UnaryExp → • UnaryOp UnaryExp
PrimaryExp → • '(' Exp ')'
PrimaryExp → • Number
UnaryOp → • '+'
UnaryOp → • '-'
UnaryOp → • '!'
Number → • INT_CONST这里还有很多状态,这里不多做解释.
GOTO(I1, Number) = I7
PrimaryExp → Number • [归约项目]GOTO(I1, PrimaryExp) = I8
UnaryExp → PrimaryExp • [归约项目]GOTO(I1, UnaryOp) = I9
核心: UnaryExp → UnaryOp • UnaryExp
CLOSURE(I9):
UnaryExp → UnaryOp • UnaryExp
UnaryExp → • PrimaryExp
UnaryExp → • UnaryOp UnaryExp
PrimaryExp → • '(' Exp ')'
PrimaryExp → • Number
UnaryOp → • '+'
UnaryOp → • '-'
UnaryOp → • '!'
Number → • INT_CONST这里也还有很多状态,不过不再多做解释.
GOTO(I1, UnaryExp) = I10
Exp → UnaryExp • [归约项目]GOTO(I1, Exp) = I11
Stmt → RETURN Exp • ';'GOTO(I11, ’;’) = I12
Stmt → RETURN Exp ';' • [归约项目]GOTO(I0, Stmt) = I13
S' → Stmt • [接受项目]第二步:构造分析表
ACTION 表
| 状态 | RETURN | INT_CONST | ’+' | '-' | '!' | '(' | ')' | ';‘ | $ |
|---|---|---|---|---|---|---|---|---|---|
| I0 | s1 | ||||||||
| I1 | s2 | s3 | s4 | s5 | s6 | ||||
| I2 | r10 | r10 | r10 | r10 | r10 | r10 | |||
| I3 | r7 | r7 | r7 | r7 | r7 | r7 | |||
| I4 | r8 | r8 | r8 | r8 | r8 | r8 | |||
| I5 | r9 | r9 | r9 | r9 | r9 | r9 | |||
| I6 | s2 | s3 | s4 | s5 | s6 | ||||
| I7 | r6 | r6 | r6 | r6 | r6 | r6 | |||
| I8 | r3 | r3 | r3 | ||||||
| I9 | s2 | s3 | s4 | s5 | s6 | ||||
| I10 | r2 | r2 | r2 | ||||||
| I11 | s12 | ||||||||
| I12 | r1 | ||||||||
| I13 | acc | ||||||||
| … | … | … | … | … | … | … | … | … |
GOTO 表
| 状态 | Stmt | Exp | UnaryExp | PrimaryExp | UnaryOp | Number |
|---|---|---|---|---|---|---|
| I0 | 13 | |||||
| I1 | 11 | 10 | 8 | 9 | 7 | |
| I6 | 14 | 15 | 16 | 17 | 18 | |
| I9 | 19 | 8 | 9 | 7 |
- s = shift(移入)
- r = reduce(归约,数字表示产生式编号)
- acc = accept(接受)
现在我们来看看一个具体的示例吧.
模拟解析 return +42;
输入 Token 序列
[RETURN, '+', INT_CONST(42), ';', $]详细的 Shift/Reduce 过程
| 步骤 | 栈 | 状态栈 | 输入 | 查表 | 动作 | 说明 |
|---|---|---|---|---|---|---|
| 1 | [] | [I0] | RETURN +42;$ | ACTION[I0][RETURN] = s1 | shift 1 | 移入 RETURN,转到状态 I1 |
| 2 | [RETURN] | [I0,I1] | +42;$ | ACTION[I1][+] = s3 | shift 3 | 移入 +,转到状态 I3 |
| 3 | [RETURN,+] | [I0,I1,I3] | 42;$ | ACTION[I3][INT_CONST] = r7 | reduce 7 | 用规则 7:UnaryOp → ’+’ 归约 |
归约过程详解(步骤 3):
1. 规则 7:UnaryOp → '+' 需要弹出 1 个符号
2. 弹出:栈变成 [RETURN],状态栈变成 [I0,I1]
3. 压入 UnaryOp:栈变成 [RETURN, UnaryOp]
4. 查 GOTO[I1][UnaryOp] = 9:状态栈变成 [I0,I1,I9]| 步骤 | 栈 | 状态栈 | 输入 | 查表 | 动作 | 说明 |
|---|---|---|---|---|---|---|
| 4 | [RETURN,UnaryOp] | [I0,I1,I9] | 42;$ | ACTION[I9][INT_CONST] = s2 | shift 2 | 移入 42,转到状态 I2 |
| 5 | [RETURN,UnaryOp,42] | [I0,I1,I9,I2] | ;$ | ACTION[I2][;] = r10 | reduce 10 | 用规则 10:Number → INT_CONST 归约 |
归约过程详解(步骤 5):
1. 规则 10:Number → INT_CONST 需要弹出 1 个符号
2. 弹出:栈变成 [RETURN,UnaryOp],状态栈变成 [I0,I1,I9]
3. 压入 Number:栈变成 [RETURN,UnaryOp,Number]
4. 查 GOTO[I9][Number] = 7:状态栈变成 [I0,I1,I9,I7]| 步骤 | 栈 | 状态栈 | 输入 | 查表 | 动作 | 说明 |
|---|---|---|---|---|---|---|
| 6 | [RETURN,UnaryOp,Number] | [I0,I1,I9,I7] | ;$ | ACTION[I7][;] = r6 | reduce 6 | 用规则 6:PrimaryExp → Number 归约 |
| 7 | [RETURN,UnaryOp,PrimaryExp] | [I0,I1,I9,I8] | ;$ | ACTION[I8][;] = r3 | reduce 3 | 用规则 3:UnaryExp → PrimaryExp 归约 |
| 8 | [RETURN,UnaryOp,UnaryExp] | [I0,I1,I9,I19] | ;$ | ACTION[I19][;] = r4 | reduce 4 | 用规则 4:UnaryExp → UnaryOp UnaryExp 归约 |
归约过程详解(步骤 8):
1. 规则 4:UnaryExp → UnaryOp UnaryExp 需要弹出 2 个符号
2. 弹出:栈变成 [RETURN],状态栈变成 [I0,I1]
3. 压入 UnaryExp:栈变成 [RETURN,UnaryExp]
4. 查 GOTO[I1][UnaryExp] = 10:状态栈变成 [I0,I1,I10]| 步骤 | 栈 | 状态栈 | 输入 | 查表 | 动作 | 说明 |
|---|---|---|---|---|---|---|
| 9 | [RETURN,UnaryExp] | [I0,I1,I10] | ;$ | ACTION[I10][;] = r2 | reduce 2 | 用规则 2:Exp → UnaryExp 归约 |
| 10 | [RETURN,Exp] | [I0,I1,I11] | ;$ | ACTION[I11][;] = s12 | shift 12 | 移入 ;,转到状态 I12 |
| 11 | [RETURN,Exp,;] | [I0,I1,I11,I12] | $ | ACTION[I12][$] = r1 | reduce 1 | 用规则 1:Stmt → RETURN Exp ’;’ 归约 |
归约过程详解(步骤 11):
1. 规则 1:Stmt → RETURN Exp ';' 需要弹出 3 个符号
2. 弹出:栈变成 [],状态栈变成 [I0]
3. 压入 Stmt:栈变成 [Stmt]
4. 查 GOTO[I0][Stmt] = 13:状态栈变成 [I0,I13]| 步骤 | 栈 | 状态栈 | 输入 | 查表 | 动作 | 说明 |
|---|---|---|---|---|---|---|
| 12 | [Stmt] | [I0,I13] | $ | ACTION[I13][$] = acc | accept | 解析成功! |
编译器,真神奇吧.
回到 一元运算 IR 的 生成. 由于我们只会在访问 Unaryexp 并且 这是一个 UNARYEXP 类型 ,并且他的 unaryexp 指针指向 primaryexp 的时候才会生产一条指令 , 那么我得 visitUnaryExp 形式会蛮复杂的.
我现在发现,我设计的这个 IR ,可以非常方便的拓展到不同的 IR 形式,不仅是 Koopa IR , 只需要添加新的 Dump 函数就可以直接生产 LLVM IR.
9-26
中间咕咕了一会,在昨天把 3.1 的生成 koopa IR 的部分通过了.
一些 debug 趣闻:
不要使用这种弱智写法
if(ast -> NUMBER){
...
}NUMBER 只是一个枚举的类型,不是成员.
不要忘记删掉断点…
To_RiscV() 的时候 Sub 操作的判断有些麻烦.
你要判断 left 和 right 的类型 ,并且如果是 Integer 形的话,还要判断其是否为 0.
大概的判断流程是这样.
SUB 操作的逻辑判断表
| 左操作数类型 | 左操作数值 | 右操作数类型 | 右操作数值 | 生成的 RISC-V 代码 |
|---|---|---|---|---|
| 立即数 | 0 | 立即数 | 0 | sub t?, x0, x0 |
| 立即数 | 0 | 立即数 | 非 0 | li t_temp, 右值; sub t?, x0, t_temp |
| 立即数 | 0 | 寄存器 | - | sub t?, x0, 右寄存器 |
| 立即数 | 非 0 | 立即数 | 0 | li t?, 左值; sub t?, t?, x0 |
| 立即数 | 非 0 | 立即数 | 非 0 | li t?, 左值; li t_temp, 右值; sub t?, t?, t_temp |
| 立即数 | 非 0 | 寄存器 | - | li t?, 左值; sub t?, t?, 右寄存器 |
| 寄存器 | - | 立即数 | 0 | sub t?, 左寄存器, x0 |
| 寄存器 | - | 立即数 | 非 0 | li t_temp, 右值; sub t?, 左寄存器, t_temp |
| 寄存器 | - | 寄存器 | - | sub t?, 左寄存器, 右寄存器 |
比 koopa IR 复杂多了.
然后就是关于 EQ 操作的一些问题.
如果 EQ 操作的 left 是一个寄存器的话,要使用 mv 指令 而非 li 指令.
这样就顺利的通过了 3.1 的所有测试.
9-28
Lv3.2. 算术表达式
本节增加了这些 ENBF 规则
Exp ::= AddExp;
PrimaryExp ::= ...;
Number ::= ...;
UnaryExp ::= ...;
UnaryOp ::= ...;
MulExp ::= UnaryExp | MulExp ("*" | "/" | "%") UnaryExp;
AddExp ::= MulExp | AddExp ("+" | "-") MulExp;由于上一节写 sub 操作花了大量的时间,列出了所有情况,而 ADD MUL DIV MOD 的 To_RiscV() 和 SUB 操作几乎一模一样,所以直接 复制粘贴即可 .
不过现在就会出现一个非常大的问题了
根据 koopa IR
fun @main(): i32 {
%entry:
%0 = mul 2, 3
%1 = add 1, %0
ret %1
}对应的示例的 RiscV 是
li t0, 2
li t1, 3
mul t1, t0, t1
li t2, 1
add t2, t1, t2不过我目前的寄存器结果返回的策略是,将 IR 中临时变量的第一位 result_name[1] 取出来当 reg_num ,这就导致一个问题, 如果我二元操作的 left 和 right 都是立即数,那么就会有问题,像这样:
.text
.global main
main:
li t0, 2
li t0, 3
mul t0, t0, t0
li t1, 1
add t1, t1, t0
mv a0, t1
ret 和示例 RiscV 不一致,这就很麻烦了,最后返回的寄存器 reg_num 和 IR 的 num 不一样.
并且 RiscV 的临时寄存器只有 7 位.
我最后使用了一种 ai 给的比较蠢的方法,如果左右两边是两个立即数的话,使用一个固定寄存器去存这个数就好了
比如使用 t6 去存 第二次 li 操作.
那么就得到这个结果:
.text
.global main
main:
li t0, 2
li t6, 3
mul t0, t0, t6
li t1, 1
add t1, t1, t0
mv a0, t1
ret这样就得到了一个目前我能接受的结果,通过了 19 个测试,不过后续还是需要重构的,因为我想了一下,如果有 100 条 add 指令,那么我这个 To_RiscV() 就玩完了.
看看 LV4 的时候 maxxing 怎么说吧.
Lv3.3. 比较和逻辑表达式
本节我要完成一下内容,
Exp ::= LOrExp;
PrimaryExp ::= ...;
Number ::= ...;
UnaryExp ::= ...;
UnaryOp ::= ...;
MulExp ::= ...;
AddExp ::= ...;
RelExp ::= AddExp | RelExp ("<" | ">" | "<=" | ">=") AddExp;
EqExp ::= RelExp | EqExp ("==" | "!=") RelExp;
LAndExp ::= EqExp | LAndExp "&&" EqExp;
LOrExp ::= LAndExp | LOrExp "||" LAndExp;和上一节基本没啥区别,就是多了一些要在 lexer 里的操作.
关于逻辑 与 和 或 操作 A && B or A || B 操作 我构建的 IR 流程是直接生成 (A ne 0) | (B ne 0) or (A ne 0) & (B ne 0) 即可,不过并没有短路优化啥的.
10-9
咕咕了好久,这几天一直在忙 linux 宣讲会的事情,搞好了 Archinstall 双系统安装的网站,以及为我而博客网站添加了许多内容.
重构了 BinaryIRValue::To_RiscV() 现在有一个更通用的表示函数
void BinaryIRValue::To_RiscV() const {
char reg_num = result_name[1];
reg_num = char('0' + (((reg_num)-'0') % 6));
auto left_int = dynamic_cast<IntegerIRValue*>(left.get());
auto right_int = dynamic_cast<IntegerIRValue*>(right.get());
// 根据操作类型选择指令名称
std::string op_name;
switch (operation) {
case ADD: op_name = "add"; break;
case SUB: op_name = "sub"; break;
case MUL: op_name = "mul"; break;
case DIV: op_name = "div"; break;
case MOD: op_name = "rem"; break;
case LT: op_name = "slt"; break;
case GT: op_name = "sgt"; break;
case AND: op_name = "and"; break;
case OR: op_name = "or"; break;
// 比较操作需要特殊处理
case EQ:
case NE:
case LE:
case GE:
emitComparisonOp(operation, reg_num, left_int, right_int);
return;
default:
std::cout << " # Unknown operation" << std::endl;
return;
}
// 统一处理算术和逻辑运算
emitBinaryOp(op_name, reg_num, left_int, right_int);
}然后再根据 立即数与寄存器的 4 种排列方式写 4 个 Dump 函数, 还可以给一些特定运算进行优化。
testcase 27 会出现超过 6 条语句,那么我们 RiscV 的六个临时寄存器肯定是不够用的, 将 regnum 的策略改成 mod 6 就可以临时解决了,不过等后面还是要写更现代的图着色寄存器分配的。
这样就把 LV3 的内容全部完成了。
Lv4. 常量与变量
Lv4.1. 常量
强度要上来了,本章要完成这些内容
CompUnit ::= FuncDef;
Decl ::= ConstDecl | VarDecl;
ConstDecl ::= "const" BType ConstDef {"," ConstDef} ";";
BType ::= "int";
ConstDef ::= IDENT "=" ConstInitVal;
ConstInitVal ::= ConstExp;
VarDecl ::= BType VarDef {"," VarDef} ";";
VarDef ::= IDENT | IDENT "=" InitVal;
InitVal ::= Exp;
FuncDef ::= FuncType IDENT "(" ")" Block;
FuncType ::= "int";
Block ::= "{" {BlockItem} "}";
BlockItem ::= Decl | Stmt;
Stmt ::= LVal "=" Exp ";"
| "return" Exp ";";
Exp ::= LOrExp;
LVal ::= IDENT;
PrimaryExp ::= "(" Exp ")" | LVal | Number;
Number ::= INT_CONST;
UnaryExp ::= PrimaryExp | UnaryOp UnaryExp;
UnaryOp ::= "+" | "-" | "!";
MulExp ::= UnaryExp | MulExp ("*" | "/" | "%") UnaryExp;
AddExp ::= MulExp | AddExp ("+" | "-") MulExp;
RelExp ::= AddExp | RelExp ("<" | ">" | "<=" | ">=") AddExp;
EqExp ::= RelExp | EqExp ("==" | "!=") RelExp;
LAndExp ::= EqExp | LAndExp "&&" EqExp;
LOrExp ::= LAndExp | LOrExp "||" LAndExp;
ConstExp ::= Exp;新加了很多内容。
10-23
我又回来做编译了,刚打完 ASC 校赛
其中很有意思的是关于带有大括号的语法,比如
Block ::= '{' {BlockItem} '}'这种 ENBF 的 语法分析该如何实现呢?
在 LR PARSER 中可以使用递归的 bison 规则,比如这样
%ast_val Block BlockItems BlockItem
Block
: BlockItems{
...
}
BlockItems
: BlockItem {
...
}
| BlockItems BlockItem{
...
}
;
当 在符号栈 中 第一次 匹配到 BlockItem 时,通过查表 reduce 出 一个 BlockItems, 此时 再 shift 进一个 BlockItem 时,符号栈中有 BlockItems 和 BlockItem , 通过查表 reduce 出一个新的 BlockItems 列表,以此类推。
感觉这种方式在 LR PARSER 里比较容易实现, 在 LL PARSER 里可能需要一些额外的操作.
10-24
把 AST 定义与 parser 规则 定义好了。
由于现在语法规则越来越复杂, 现在需要添加一个 词法分析的阶段,即要添加一个符号表.
但是完全不知道符号表怎么写呢.
10-27
现在需要完成一个符号表,我已经把初步的 symbol 定义写好了,对于每一个 symbol ,他是一个 name , type , datatype , scope_level ,以及其本身 value 的类 , 其中 type 用来区分其 是 常量,变量,还是函数 , scope_level 用来表示生命周期(为后文做铺垫) .
另外,重构了 IRGenerator 中的 current_block 访问形式,之前是以函数的参数传递形式访问的,但是这样非常的重复冗余 , 所以现在设计一个 上下文相关的 类
struct GenContext
{
IRBasicBlock* current_block;
SymbolTable* symbol_table;
IRProgram* program;
};用来提供 block table 和 program 统一的访问接口,这样就不用在 函数参数里加一堆 IRBasicblock* current_block 以及符号表了,好看多了。
发现现在的 Generator 机制并没有 完成对 多个 block 的处理。这个以后要处理一下。
10-28
要备赛 ASC26 了,编译进度放缓。
11-10
又写了一会编译器,最近的代码时间实在是太少了,从下周开始要多写一些代码了。
符号表借鉴 ai 的写法增添了很多 rubustness 。 现在可以很方便的用 enterScope() 进入新作用域 exitScope() 退出作用域。
用 declare() 去声明一个符号, 用 lookup() 去查询一个符号。
目前相当于第四章和第五章一块写了,因为这个作用域我觉得要先写了。 现在大概可以明晰符号表的工作周期了
在生成 program 的时候创建了符号表, 当 进入 / 离开 block 的时候,进行作用域的管理。
符号表是一个 map 的 vector ,每一张 map 代表一个 作用域, 这样就可以方便的 管理同一个作用域下的 symbol 了。
其实我想了一下,一张 map 也可以管理多个作用域下的 symbol , 就是在 symbol 的属性里加入 scope 这一属性就行,但是问题就是,这样代码复杂性会高很多,并且如果要 exitScope() 的话 需要遍历所有的 symbol ,这样时间复杂度会高很多, 不过他的内存消耗会少很多。
问了 AI ,GCC 和 LLVM 都是使用的 第一种方案, 即使用多个 vector<map> 来存符号表。
现在符号表搞好了,还需要干一些事情,就是在 visitConstDef() 的时候,要把常量折叠了。 再存进符号表里面, 等后面用到 LVal 的时候再把这个加入到 IR 中 block 的 value 列表里面。
其实 半个小时就能干很多事情了。
最近有些急躁了,没干啥正事,需要矫正一下了。
今天还是 11 月 10 日
现在把 4.1 写完了, koopa IR 和 RiscV 都过了。
我把常量折叠搞完了。这样的话关于可能新增的 IRvalue 也就只有 LVAl 相关的东西了,然后会被替换成立即数,所以说 KoopaIR 和 RiscV 并没有需要新增的东西。
然后就是一些 bug 和 坑。
可以在 Flex & Bison 中开启 调试模式 来增加 额外的信息。
遇到 Bison 的 syntax error 需要系统地调试。
🔍 关于调试
方法 1:启用 Bison 调试模式
修改你的 sysy.y 文件:
%{
#include <iostream>
#include <memory>
#include <string>
#include "include/ast.h"
int yylex();
void yyerror(std::unique_ptr<BaseAST> &ast, const char *s);
using namespace std;
%}
// ✅ 添加这行:启用详细错误信息
%define parse.error verbose
// ✅ 添加这行:启用调试追踪
%define parse.trace
%parse-param { std::unique_ptr<BaseAST> &ast }方法 2:在 main.cpp 中启用调试
#include <iostream>
#include <memory>
#include "include/ast.h"
#include "include/Ir_generator.h"
using namespace std;
// ✅ 声明外部调试变量
extern int yydebug;
extern FILE* yyin;
extern int yyparse(unique_ptr<BaseAST> &ast);
int main() {
// ✅ 启用 Bison 调试输出
yydebug = 1;
auto ast = unique_ptr<BaseAST>(nullptr);
int ret = yyparse(ast);
if (ret != 0) {
cerr << "Parse failed!" << endl;
return 1;
}
// ... 其余代码
}方法 3:添加详细的错误处理
在 sysy.y 中修改 yyerror 函数:
%{
// ... 头文件 ...
// ✅ 声明外部变量
extern int yylineno;
extern char* yytext;
extern FILE* yyin;
void yyerror(std::unique_ptr<BaseAST> &ast, const char *s) {
// ✅ 输出详细错误信息
std::cerr << "Error at line " << yylineno << ": " << s << std::endl;
std::cerr << "Near token: '" << yytext << "'" << std::endl;
}
%}方法 4:在 Flex 中启用行号追踪
修改你的 sysy.l 文件:
/* filepath: /home/yoo/Documents/Compliers/LEARNING_Compilers/src/front/sysy.l */
%{
#include <cstdlib>
#include <string>
#include "include/ast.h"
#include "sysy.tab.hpp"
using namespace std;
%}
/* ✅ 启用行号追踪 */
%option yylineno
/* ✅ 启用调试 */
%option debug
%%
/* ... 词法规则 ... */开启 debug 选项后,得到的信息就多了,我出现的问题原来是这个
Error at line 2: syntax error, unexpected $undefined, expecting EQ
Near token: '='这样我就懂了。
我们期望得到一个 赋值符号 = 不过我在语法规则里设置的是 EQ 也就是 == 那么就会有问题了。
总之,我最后 在 main 函数里面写了一个 -debug 的 选项,用来开始 flex 和 bison 的调试模式。
然后就是关于 Bison 的一些小知识,重新学习了一下,以下内容可以定义 token 的优先级,越往下优先级越高。
%left '='
%left LOR
%left LAND
%left EQ NE
%left LT LE GT GE
%left '+' '-'
%left '*' '/' '%'汇总一下这一节做完的事情:
- 添加了常量相关的 AST 以及 lexer, parser 规则。
- 添加了常量折叠函数。
- 添加了符号表
- 并且有作用域管理
Lv4.2. 变量
我让 gemini 写了一篇关于介绍 AI 编译器的文章,之前一直不太了解 AI 编译器,现在对这个有一些了解了,link↗
11.25
在变量这一小节,我们需要实现以下 EBNF
Decl ::= ConstDecl | VarDecl;
ConstDecl ::= ...;
BType ::= ...;
ConstDef ::= ...;
ConstInitVal ::= ...;
VarDecl ::= BType VarDef {"," VarDef} ";";
VarDef ::= IDENT | IDENT "=" InitVal;
InitVal ::= Exp;
...
Block ::= ...;
BlockItem ::= ...;
Stmt ::= LVal "=" Exp ";"
| "return" Exp ";";总的来说,要完成变量相关的 三种新 IR (alloc store load) 的编写,以及相关联的符号表内容。
照着常量的定义写完了新的 AST 定义 以及 parser 规则的编写
一个我常出现的bug
/usr/bin/ld: CMakeFiles/compiler.dir/src/backend/Ir_generator.cpp.o: in function `IRGenerator::visitDecl(DeclAST const*)':
/root/compiler/src/backend/Ir_generator.cpp:118: undefined reference to `typeinfo for VarDeclAST'
/usr/bin/ld: CMakeFiles/compiler.dir/src/backend/Ir_generator.cpp.o: in function `IRGenerator::visitVarDecl(VarDeclAST const*)':
/root/compiler/src/backend/Ir_generator.cpp:258: undefined reference to `typeinfo for VarDefsAST'链接出现问题, 这是在头文件中申明了函数但是最后没有在 .cpp 文件定义的问题。补上声明就行。
我在中途犯了一个愚蠢的问题,我试图将变量的 InitVal 进行常量折叠,忘记了有的变量在程序运行时候才会被赋值,不过类似
int x = 10;这样的变量申明,后续有优化,名字叫 常量传播
还没写 IR 和 RiscV 的 Dump 函数,不过已经能额外多过一个测试点了.
给买了哈基米1年的号,用了用那个动态视图模式,这个确实初看上去非常惊艳,但是用了一会发现了问题,前端不够精细,会有不美观的地方,一次性生成的内容量较少。
再者就是使用 nano banana pro 的体验,非常良好,我让他生成了一副魂魄妖梦的连环画,我给他的 prompt 是

然后他输出了一些关于生图的 tag,我转手再问了他一次。他给出的连环画是这样的

我只能说,给 🍌 👴 👻 了.
今天先到此为止吧.
11-26
搞完了 IR 的 Dump()
把之前的有些内容忘记了,以为我自己写错了 IRGenerator 里的 VisitVarDef store 相关的内容
if(auto initval = dynamic_cast<InitValAST*>(ast->initval.get())){
if(auto exp = dynamic_cast<ExpAST*>(initval ->exp.get())){
auto var_value = visitExp(exp);
auto store = std::make_unique<StoreIRValue>(std::move(var_value),var_name);
ctx.current_block->ADD_Value(std::move(store));
}
}关于 StoreIRValue 的第一个参数,现在是一个 TemporaryIRValue ,我忘记 visitEXP() 的时候就会把赋值内容里的 Value 添加到 Block 里了。
实际上这段代码没问题 ()
然后就是 To_RiscV() 的内容了
这部分比较复杂,涉及到了函数,变量的栈帧,我需要设计一个 StackFrameManager 类,来管理栈帧,为了知道每一条和内存相关的 IRValue 所产生的 offset 我们需要遍历一个 Functino 两次,第一次计算 offset 第二次再正常的 To_RiscV .
在这个 StackFrameManager 里面,得有一张 map 来映射 每个变量 和 其 offset 这样在第二次 Dump() 的时候,编译器才知道要移动几位.
然后我打算将这个 stack 添加到 之前的 GenContext 里面,然后再添加一个全局的访问点, 也就是类的 静态成员, 这样就可以全局访问一个 stack 了.
然后我们在这个栈上计算 offset 存在表里, 当我们下一次访问到一个 TemporaryIRValue 类型的变量时,直接查表,然后使用 lw 指令就能把栈上的 那一块对应区域加载到寄存器里了。
lw 寄存器1, 偏移量(寄存器2) 的含义是将 寄存器2 的值和 偏移量 相加作为内存地址, 然后从内存中读取一个 32 位的数据放到 寄存器1 中.
sw 寄存器1, 偏移量(寄存器2) 的含义是将 寄存器2 的值和 偏移量 相加作为内存地址, 将 寄存器1 中的值存入到内存地址对应的 32 位内存空间中.
lw/sw 中偏移量的范围和 addi 一致.
AI 帮我把之前的 寄存器分配 的 屎山 删除了,以前在进行愚蠢的 IR 符号到 临时 寄存器的映射 非常的好笑,现在的寄存器分配策略正如文档中说的,不分配寄存器,全部存在栈上面。
现在的 BinaryIRValue 变的清爽很多了。直接判断左右 value 的类型,然后加载到t0 t1 寄存器,最后把结果存在 t0 就行了,所以全程只用两个寄存器。
也是通过了 To_RiscV()
Lv5. 语句块和作用域
因为之前写了符号表的 enter_scope() 和 exit_scope() 所以说语义分析部分不需要重新写了。
仅需要在语法分析 添加新的 stmt 的 ebnf 语句即可。 然后IR 的话都是之前的,比较方便。
这样可以通过 3 个测试点。
EBNF 里没有讲 { } 这样也是一个 block , 将其添加到语法规则后 过了 5 个测试点。
然后就是不同作用域的同名变量的问题了。 这在语法中是允许的,但是当生成IR 的时候,IR 的 NAME 不能有 重复的 名称。 比如
int main(){
int a;
{
int a;
{
int a;
}
}
}这样的,按之前的逻辑生成的IR 就会出现问题。
解决方案是在符号表里添加一个 新的 ir_name 选项即可,再利用一个 map 去计数,给 ir_name 添加数字,比如上面的 ir_name 分别是 @a, @a_1, @a_2 .
这样就没啥问题了,进入下一章
Lv6. if 语句
12-4
if 语句的 ast,以及 bison 规则比较好写,因为没啥要写的() 。
关于 if else 的二义性问题,因为 我们现在使用的 是 LR(1) 的 parser ,所以我们只需要 在 stmt 的 reduce 规则里 加上 if 以及 if else 就会自动完成 if else 的就近匹配。
然后就是关于 IR 生成相关的问题了。
if 语句会创建新的 IR Basicblock 这是个挺麻烦的事情 ,在哪里创建。
在每一个 IF 类型的 Stmt 里创建新的 block 即可。
关于一些问题:
假如 then 块语句最后一条是 return , 那么就不需要 jump 了。
在生成 riscv 的时候,命名块的取名也有些要求的,当我使用 then1 end2 (和IR 中的 类似)这种命名方式命名的时候,出现了错误。
stderr:
ld.lld: error: undefined symbol: then1
>>> referenced by /tmp/tmpkd6wedja/5aa8aac25c2d4d89a6a3e405c5a51ed6.o:(.text+0x60)不过好像和命名没什么关系。
在 RiscV中 .L 开头的符号通常被汇编器视为局部符号(Local Symbol),不会被导出到符号表,也不会与全局函数名冲突。 我们把之前的 then1 改成 .Lthen1 这种形式,一下子多过了3个测试点。如果使用先前的命名方案,如果后续有出现命名成 then1 的函数 ,那在汇编器的符号表中就会出现重复定义的问题,这是一个很大的隐患。
此外还有一些问题,我使用 ctx.current_blovk->ir_value.back().get() 检查当前最后一条指令是否是 ReturnIRValue 类型的时候,没有加是否为空的判断 然后就 Segmentation fault 了。
添加检查即可通过。
之后通过了所有的 riscv 输出,但是有两个 koopaIR 类型的没有通过。
这非常奇怪。
running test "5_more_logical" ... CASE ASSEMBLE ERROR
stdout:
stderr:
error: expected character ':', found character '='
at /tmp/tmpqopqdkfq/9ea63676d65144a599480d619d662889.S:100:7
|
100 | %56 = load @d
| ^
1 error emitted
running test "6_multiple_returns" ... CASE ASSEMBLE ERROR
stdout:
stderr:
error: expected basic block name, found keyword 'ret'
at /tmp/tmpqopqdkfq/9ea63676d65144a599480d619d662889.S:6:3
|
6 | ret 4
| ^^^
1 error emitted这是错误信息。
然后对应的测试点五是
int main() {
int a = 1 || 2 && 3;
int b = 0 && 1 || 0;
int c = (1 && 0 || 1) * 4;
int d = 5;
const int e = 6 || 7 && 8;
if (a == 1 || a == 2);
if (b == 0 || b == 1) d = d + 1; else;
if (a && b || c && d) d = d + e;
return d || !c;
return d || e;
}那最后两条 return 应该是在同一个 block 里面的。
那么这和 koopaIR 的规范冲突了,koopaIR 的每一个 basicblock 只允许一条 ret 或 jump 做结尾。
那么就得做一定程度的 死代码消除 。
一个 Block 中最早 的 return jump branch 类型 的 Value 后的所有 Value 都被跳过。
然后就可以了。顺利完成 6.1 的所有内容。
对于 6.2 ,我之前在 BinaryIRValue 有写过短路, 所以自动完成了。
Lv7. while 语句
Lv7.1 while部分
12-7
这次我要手写 while, 照着 if 写 就行了。
还是比较容易的。
注意,在 while_body 里也要进行 死代码消除 。
Lv7.2 break & continue
新加了两个 stmt 类型。然后,我们需要一个数据结构去存break 或者 continue 需要跳转到的 block(来自手册)。
那肯定要使用 stack 了。
原来这玩意的名字是 循环栈 loop_stack .
loop栈还是很好设计的,然后把他加到 GenContext 里管理就可以了。
现在我的 GenContext 是这样的。
struct LoopInfo {
std::string entry_label;
std::string end_label;
};
struct GenContext
{
IRBasicBlock* current_block = nullptr;
SymbolTable* symbol_table = nullptr;
IRProgram* program = nullptr;
StackFrameManager stack;
std::vector<LoopInfo> loop_stack;
static GenContext* current_ctx;
};
写好之后 在 while 相关 IR 创建 block 的时候 将当前信息 加入 ctx.loop_stack 即可.
然后关于语义分析,只需要判断循环栈是否为空即可 。
然后就顺利的完成了这一小节
Lv8. 函数与全局变量
Lv8.1 函数的定义和调用
CompUnit ::= [CompUnit] FuncDef;
FuncDef ::= FuncType IDENT "(" [FuncFParams] ")" Block;
FuncType ::= "void" | "int";
FuncFParams ::= FuncFParam {"," FuncFParam};
FuncFParam ::= BType IDENT;
UnaryExp ::= ...
| IDENT "(" [FuncRParams] ")"
| ...;
FuncRParams ::= Exp {"," Exp};这节加入的 ENBF 有这些。 正常添加即可,不过对于第一条 CompUnit 的内容,之前在 Bison 文件中 CompUnit 是程序的开始,负责传递最后的 ast 结构。现在添加了新的 规则后 CompUnit 的 $$ 和 最后 move 到 ast 的值就冲突了。
这时候添加了一个
%start Root负责传递最终的 ast 。这样就不会冲突了。
然后是 IR 相关的 内容。
主要新增的内容是:
- 在符号表中添加函数类型,用来注册,添加全局作用域
- 重构 visitFundef 函数,添加 注册函数 , 给参数添加 IR 等内容
- 在 visitUnaryExp 函数中 添加 调用函数相关的 IR.
主要是新的 visitFundef 的内容,这次重构有了一个比较明确的顺序
- 在全局符号表中声明函数名称
- enterscope (为了参数)
- 生成 FunIR ,添加参数
- visit block
- 确保每个函数都有 返回值
目标代码生成
接下来就是生成 IR 了, 和 第四章类似, 我们会对 栈帧 进行操作。
具体的流程是:
- 扫描每一个函数,类似于之前的变量,分别计算 S (局部变量) + R (ra) + A (传参空间)。R 的计算方法: 如果函数中出现了 call, 则为 4, 否则为 0. A 的计算方法: 所有
Call指令 对应函数参数最多值 - 8 后 * 4,若少于等于 8 个则为 0。 - 计算栈帧总大小 S’ = (S + R + A + 15) / 16 * 16
- 这个将在 prologue 和 epilogue 的时候使用
- 生成 prologue: 首先, 根据 S′ 生成 addi 指令来更新 sp. 然后, 如果 R 不为 0, 在 sp+S′−4 对应的栈内存中保存 ra 寄存器的值.
- 生成函数体中的指令.
- 如果遇到 Koopa IR 中的 call 指令, 你需要先将其所有参数变量的值读出, 存放到参数寄存器或栈帧中, 然后再生成 RISC-V 的 call.
- 生成 epilogue: 如必要, 从栈帧中恢复 ra 寄存器. 然后, 复原 sp 寄存器的值. 最后生成 ret.
然后几个我曾有疑问的点:
- 每个函数单独计算栈帧,各自管理。
- sp 遍历一轮函数后会回到原点。
- ra 寄存器负责存call 函数的下一条指令。
顺带一提,函数的参数会存在 a0-a7 这几个寄存器中,若参数多余8个,将会存在本函数底部的栈帧中。
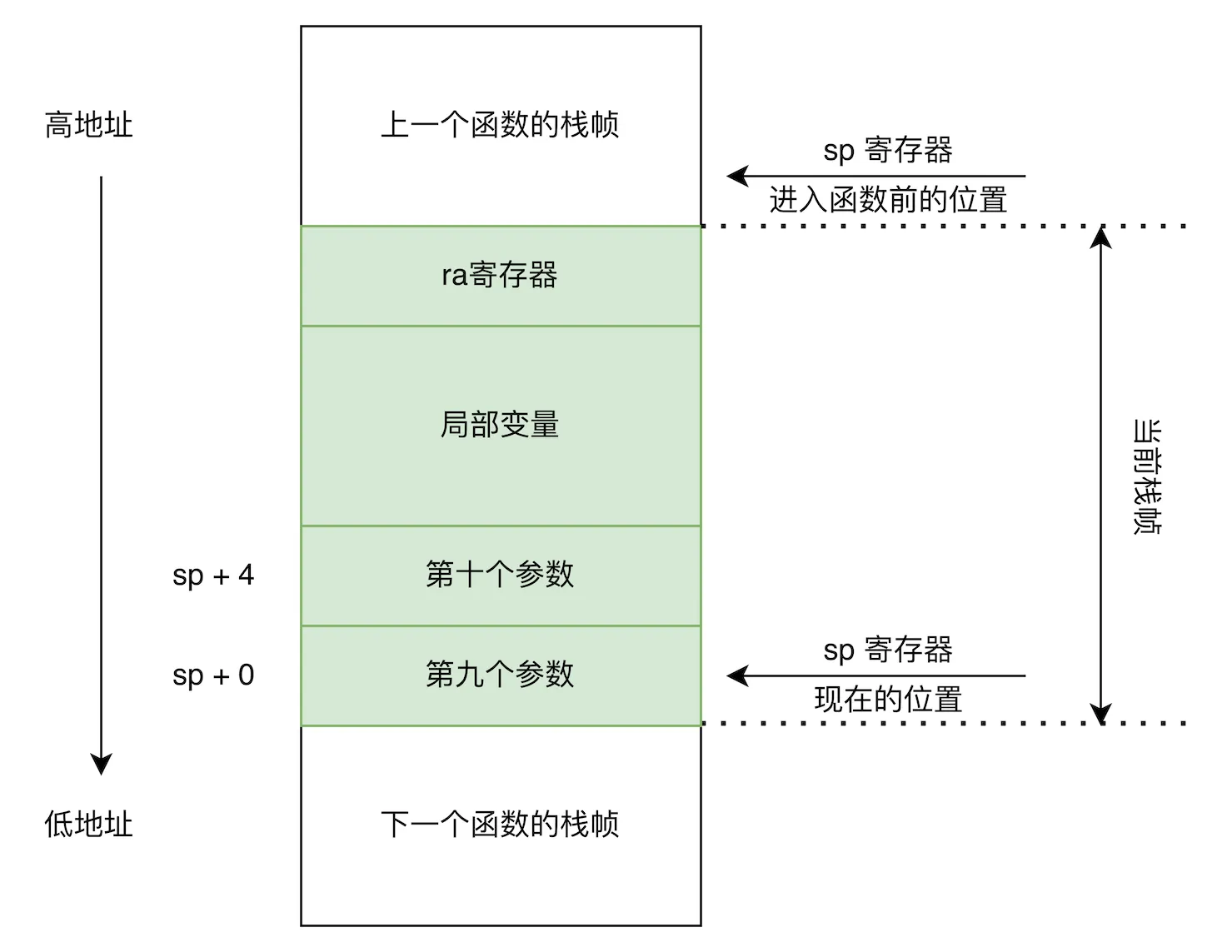
然后被调用的函数如果想要读第九个参数,只需要访问 sp + S‘ 即可。即访问了上一个函数的底部的栈帧中的第九个参数。
之后就顺利完成了。
Lv8.2 SysY 库函数
对于通过测试点来说。
提前在符号表申明 库函数 即可。
然后类似 cpp 的 include 预处理。 把函数的声明放到所有 IR 的最前面就行了。
Lv8.3 全局变量和常量
照常写了 parser 的规则后,parser 报错了,错误是这样
root@a79448fdad14:~/compiler/build# ./compiler -koopa ../hello.c -o hello.koopa -debug
Starting parse
Entering state 0
Reading a token: --(end of buffer or a NUL)
--accepting rule at line 42 ("int")
Next token is token INT ()
Shifting token INT ()
Entering state 1
Reducing stack by rule 11 (line 167):
$1 = token INT ()
-> $$ = nterm FuncType ()
Stack now 0
Entering state 7
Reading a token: --accepting rule at line 38 (" ")
--accepting rule at line 52 ("var")
Next token is token IDENT ()
Shifting token IDENT ()
Entering state 17
Reading a token: --accepting rule at line 71 (";")
Next token is token ';' ()
Error at line 1: syntax error, unexpected ';', expecting '('
Near token: ';'
Error: popping token IDENT ()
Stack now 0 7
Error: popping nterm FuncType ()
Stack now 0
Cleanup: discarding lookahead token ';' ()
Stack now 0
ERROR: yyparse returned 1
Parse failed!
ps: 还好之前写了 -debug 模式,前人种树后人乘凉这一块.
大致的信息就是,读入了 int var;但是和
FuncDef ::= FuncType IDENT "(" [FuncFParams] ")" Block;这条规则不匹配。
这就很奇怪了,不应该进行全局变量相关的 reduce 吗;
然后我们再来看看 语法规范
CompUnit ::= [CompUnit] (Decl | FuncDef);
Decl ::= ConstDecl | VarDecl;
ConstDecl ::= "const" BType ConstDef {"," ConstDef} ";";
BType ::= "int";
ConstDef ::= IDENT "=" ConstInitVal;
ConstInitVal ::= ConstExp;
VarDecl ::= BType VarDef {"," VarDef} ";";
VarDef ::= IDENT | IDENT "=" InitVal;
InitVal ::= Exp;
FuncDef ::= FuncType IDENT "(" [FuncFParams] ")" Block;
FuncType ::= "void" | "int";
FuncFParams ::= FuncFParam {"," FuncFParam};
FuncFParam ::= BType IDENT;
Block ::= "{" {BlockItem} "}";
BlockItem ::= Decl | Stmt;
Stmt ::= LVal "=" Exp ";"
| [Exp] ";"
| Block
| "if" "(" Exp ")" Stmt ["else" Stmt]
| "while" "(" Exp ")" Stmt
| "break" ";"
| "continue" ";"
| "return" [Exp] ";";
Exp ::= LOrExp;
LVal ::= IDENT;
PrimaryExp ::= "(" Exp ")" | LVal | Number;
Number ::= INT_CONST;
UnaryExp ::= PrimaryExp | IDENT "(" [FuncRParams] ")" | UnaryOp UnaryExp;
UnaryOp ::= "+" | "-" | "!";
FuncRParams ::= Exp {"," Exp};
MulExp ::= UnaryExp | MulExp ("*" | "/" | "%") UnaryExp;
AddExp ::= MulExp | AddExp ("+" | "-") MulExp;
RelExp ::= AddExp | RelExp ("<" | ">" | "<=" | ">=") AddExp;
EqExp ::= RelExp | EqExp ("==" | "!=") RelExp;
LAndExp ::= EqExp | LAndExp "&&" EqExp;
LOrExp ::= LAndExp | LOrExp "||" LAndExp;
ConstExp ::= Exp;发现这两条有问题
FuncType: INT | VOID
BType: INT解析器看到 int var; 时,遇到 INT token 后有两种归约可能:
归约为 FuncType(期待函数定义) 归约为 BType(期待变量声明)
这是一个 reduce-reduce 冲突.
说明 maxxing 文档写错了(以汇报该错误).
然后比较规范的解决方法就是重新设计 EBNF.
但是我使用了一个比较偷鸡的方法
在 sysy.y 文件开头添加 %glr-parser 指令,让 bison 生成 GLR(Generalized LR)解析器。GLR 解析器可以处理二义性语法,当遇到冲突时会并行探索多个解析路径,最终选择正确的那个.
然后前端告一段落。
关于后端,我们需要添加一个 GlobalAllocIRValue 类,生成 IR 的时候将其添加到 program 的 globalvalue 列表里面。生成对应的 dump() 和 to_RiscV() 即可。
此外还要修改LoadIRValue() 和 StoreIRValue() 相关内容。判断变量是全局变量还是局部变量。全局变量需要使用 la 指令进行生成。
很好理解全局常量不需要生成任何额外代码。
此外最后一个测试点点,短路我之前没写,现在补上了。
主要思想是将 ||,&& 操作变成一个 分支的形式
a || b =>
if(a){
true;
}
else{
b;
}
a && b =>
if(a){
b;
}
else{
false;
}差不多这样
这样就顺利完成了 lv8 的所有内容
12-16
12-18
我错了,maxxing的文档没有写错.😰😰😰😰😰😰
Parser 没法reduce != EBNF 错误.
比如说,对于所有的左递归,在 LL parser 中都是死循环,错误的.需要一些额外的改动.
类似的,在 LALR 中,没办法 规约
FuncType: INT | VOID
BType: INT也很正常,需要我手动改.
之前添加 GLR 的方法不是一个好方法,我刚发现这会使得 if-else 章节的 一个测试点出错.不应该允许二义性问题的.
我现在修改了 parser 规则 删除 FuncType 这个关键字
然后将 FuncType 改成 BType 最后再添加 额外的 VOID 形式的函数定义即可.
这个是我觉得改动最小的,逻辑上正确的形式了.
Lv9. 数组
Lv9.1 一维数组
这节需要完成
ConstDef ::= IDENT ["[" ConstExp "]"] "=" ConstInitVal;
ConstInitVal ::= ConstExp | "{" [ConstExp {"," ConstExp}] "}";
VarDef ::= IDENT ["[" ConstExp "]"]
| IDENT ["[" ConstExp "]"] "=" InitVal;
InitVal ::= Exp | "{" [Exp {"," Exp}] "}";
LVal ::= IDENT ["[" Exp "]"];这些内容.
需要设计一个新的 符号 ,以及 新的 IRValue 类型 GetelemptrIRValue.
对于常量数组的初始化列表,sysY 不会在编译时存放在符号表里.这就表示
const int a = 1 + arr[1];这样是不允许的.
数组分四个种类,全局常量,局部常量,全局变量,局部变量.其中 全局的数组 直接使用 GlobalAlloc 进行处理,申明其类型,和初始化列表,比如对于一个全局数组
// 这是个全局数组
int arr[3] = {1, 2, 3};
对应的 IR 是
global @arr = alloc [i32, 3], {1, 2, 3}常量全局数组和变量全局数组操作是一样的
然后对于局部的数组,我们使用普通的 Alloc IR 进行声明,然后再用 Getelemptr 和 Store 把 初始化列表存进去.
比如对于局部数组
int arr[5] = {1,2,3};最后的生成的 IR 是
@arr = alloc [i32, 5]
%0 = getelemptr @arr, 0
store 1, %0
%1 = getelemptr @arr, 1
store 2, %1
%2 = getelemptr @arr, 2
store 3, %2
%3 = getelemptr @arr, 3
store 0, %3
%4 = getelemptr @arr, 4
store 0, %4
对于初始化数组,如果有,且仅包含部分初始化内容,我们要对其余的位进行补零.
最后就是数组的调用, 使用 一个 getelemptr 和 load 即可.
int arr[2];
arr[1];@arr = alloc [i32, 2] // @arr 的类型是 *[i32, 2]
%ptr = getelemptr @arr, 1 // %ptr 的类型是 *i32
%value = load %ptr // %value 的类型是 i32
// 这是一段类型和功能都正确的 Koopa IR 代码目标代码生成
Lv9.2 多维数组
有时候得承认自己的天赋不足,写到这里的时候,我在处理初始列表这一块,奋斗了3小时.要从零想出来一个设计方案不简单.
parser 部分,添加新的 ArrayDeclarator 和 ArrayAddress 来表示 新的语法规则
{"[" ConstExp "]"} 添加了新的 AST 来保存 initval 和 constexp 交融的 初始列表.
数组列表展开 & 语义分析
那么如何去让一堆杂乱无章,人类看不懂的初始化列表,变成人类可读的列表呢?
比如以下列表
int arr[2][3][4] = {1, 2, 3, 4, {5}, {6}, {7, 8}};最终会被翻译成
int arr[2][3][4] = {
{{1, 2, 3, 4}, {5, 0, 0, 0}, {6, 0, 0, 0}},
{{7, 8, 0, 0}, {0, 0, 0, 0}, {0, 0, 0, 0}}
};这样一下子就能让人类看懂了.
还有比如对于
int arr1[2][3][4] = {1, 2, 3, 4, {5}};
int arr2[2][3][4] = { {5} ,1 ,2 ,3 ,4};
这两个 数组定义, {5} 所代表的含义是不同的, 第一个代表 int[4] 第二个代表 int[3][4] .
即生成的汇编为
.data
.global arr1
arr1:
.word 1
.word 2
.word 3
.word 4
.word 5
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.data
.global arr2
arr2:
.word 5
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 1
.word 2
.word 3
.word 4
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0
.word 0(偷懒没有使用 .zeroinit)
但是具体该怎么做呢?
我使用了,语义检测和扁平化数组同时进行的操作.
先看看我的 Initval 的结构
InitVal
: Exp {
auto initval = make_unique<InitValAST>(InitValAST::EXP);
initval -> exp = unique_ptr<BaseAST>($1);
$$ = initval.release();
}
| '{' InitValList '}'{
auto initval = make_unique<InitValAST>(InitValAST::ARRAY);
initval -> initlist = unique_ptr<BaseAST>($2);
$$ = initval.release();
}
| '{' '}' {
auto initval = make_unique<InitValAST>(InitValAST::ZEROINIT);
$$ = initval.release();
}
;
InitValList
: InitVal {
auto list = make_unique<InitValListAST>();
list -> initlist.push_back(unique_ptr<BaseAST>($1));
$$ = list.release();
}
| InitValList ',' InitVal {
auto list = dynamic_cast<InitValListAST*>($1);
list -> initlist.push_back(unique_ptr<BaseAST>($3));
$$ = list;
}
;Initval 和 InitValList 可以递归包含.
具体要怎么做呢?
基本思想
首先累乘 dims 得到扁平后数组 result 的大小,以及计算各维度的数组边界(stride)。
比如对于 int[2][3][4],各维度的长度分别为 2, 3 和 4:
- 总大小 = 2 × 3 × 4 = 24
- 边界值(从内到外):
- 第2维边界 = 4(最内层,每行4个元素)
- 第1维边界 = 4 × 3 = 12(每个二维子数组12个元素)
- 第0维边界 = 4 × 3 × 2 = 24(整个数组)
遍历过程
我们需要有一个 cursor 作为光标,从左到右不回头地将初始化列表的值存储到扁平数组 result。
遍历 InitVal(或 ConstInitVal,处理方式完全相同):
当遇到标量表达式(constexp/exp)时:
- 在 result[cursor] 记录该表达式的值
- cursor++
当遇到嵌套列表 {…} 时:
- 检查 cursor 的值是否与某个数组边界对齐
- 如果不对齐任何边界,则存在语义错误
- 如果对齐,记录对齐到的边界值(即该子数组的大小)
- 递归处理列表内的元素,传入剩余的子维度
- 处理完毕后,填充0到该边界(确保子数组填满)
当遇到空列表 {} 时:
- 检查 cursor 是否与某个边界对齐
- 用0填充到下一个边界位置
这样就可以同时满足语义分析和扁平化数组了.
得到扁平化数组 result 后,我没有使用参考文档里的 IR 生成方法 ,而是将所有多维数组都变成一维的数组.
比如
int a[2][3];生成的 koopaIR 为
global @a = alloc [i32,6] 而不是
global @a = alloc [[i32,3],2]这样后续的操作会少很多,况且多维数组在内存里本来就是这样存的,不是吗.
然后调用数组的时候需要使用 mul add 等指令算出来 多维数组对应的扁平化数组的地址.这个查询符号表即可.
其余的和上一节一模一样,毕竟还是一维数组.